事实驱动的 AI 视频生成器 & 导演级可控数字人
体验全球首个具备网络实时搜索与导演级动作控制的 AI 数字人视频平台。将 Markdown 文档与 TXT 文本极速转化为零幻觉、手势精准可控的专业数字人演示视频。
从原始文档到专业视频,全自动生成。
基于先进的 LLM 智能规划、语义文档检索与云端并行编译技术,在浏览器中即可创作广播级品质的数字人演示视频。
学术论文 PDF 智能检索与大纲生成
支持智能检索相关学术 PDF 文档。系统会自动分析图表与核心公式布局,精炼摘要关键内容,输出结构高度清晰的专业视频叙事大纲。
动作姿态预设控制面板
通过在工作台中灵活勾选动作姿态预设(支持挥手致意、摊手解释、点赞强调等丰富的动作库),自动与解说台词精准融合,Cuevo 将实时编译生成完美对齐的连续动作序列。
姿态预设库 (Action Presets)
30+ Ready-to-use Motion Presets for Digital Avatars
一键声音克隆与高清人像生成
您可以选择内置的官方数字人分身,或通过 Prompt 描述生成高清写实人像。配合一段 8 秒的语音样本,即可克隆您的专属声线,并实现毫秒级唇形对齐。
16+ 种专业互动式 VFX 卡片模板
以直观的视觉方式解释抽象概念。拥有 16+ 种可编程布局模板:白板草图、LaTeX 数学公式、动态代码终端,以及传统文化图表网格(如周易八卦图和紫微斗数星盘)。
需卦 (水天需)
“需于酒食,贞吉。”
紫微斗数星盘
12宫位排盘与星曜权重自动计算。
B-Roll 空镜头智能检索与精准踩点
自动切割语音旁白短句,并并行检索 Pexels 高清素材。引擎根据语音时长动态缩放、裁剪和对齐空镜头,实现声画同步的流畅切换。
无损视频翻译与音轨时长缩放对齐
在保留原始音色克隆的前提下翻译视频。包含 DeepSeek 场景基调分析、音色克隆 TTS 翻译,以及音轨时长拉伸,使翻译后的发音完美匹配原始视频画面节奏。
云端多线程并行渲染与活动队列
在云端并行启动批量渲染任务。多线程引擎同时处理视频画面层、动态 VFX 覆盖层、背景音轨,并高速合成输出高品质 MP4 视频文件。
AI 辅助功能全景库
我们为您提供丰富的专业组件库,满足各种极其细分的专业场景需求。
核心视频生成套件,支持各种素材拼接与智能剪辑
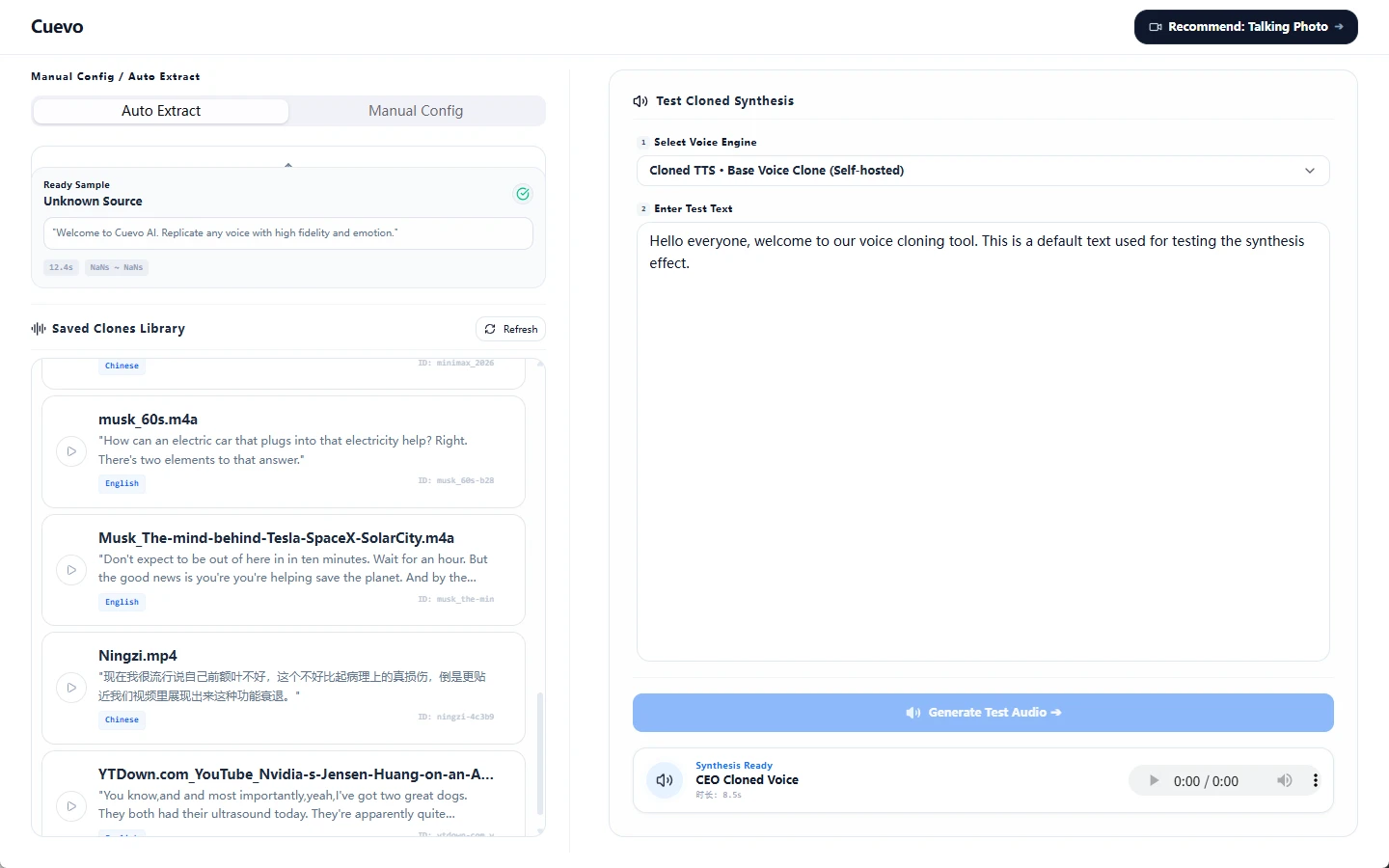
以极高的声音拟真度完美复刻任何独特的真人声线。仅需分析简短的音频样本,我们的语音大模型即可支持丰富的情感韵律合成、自然的语调起伏,并实实现在全球 100 多种语言中的无缝配音。
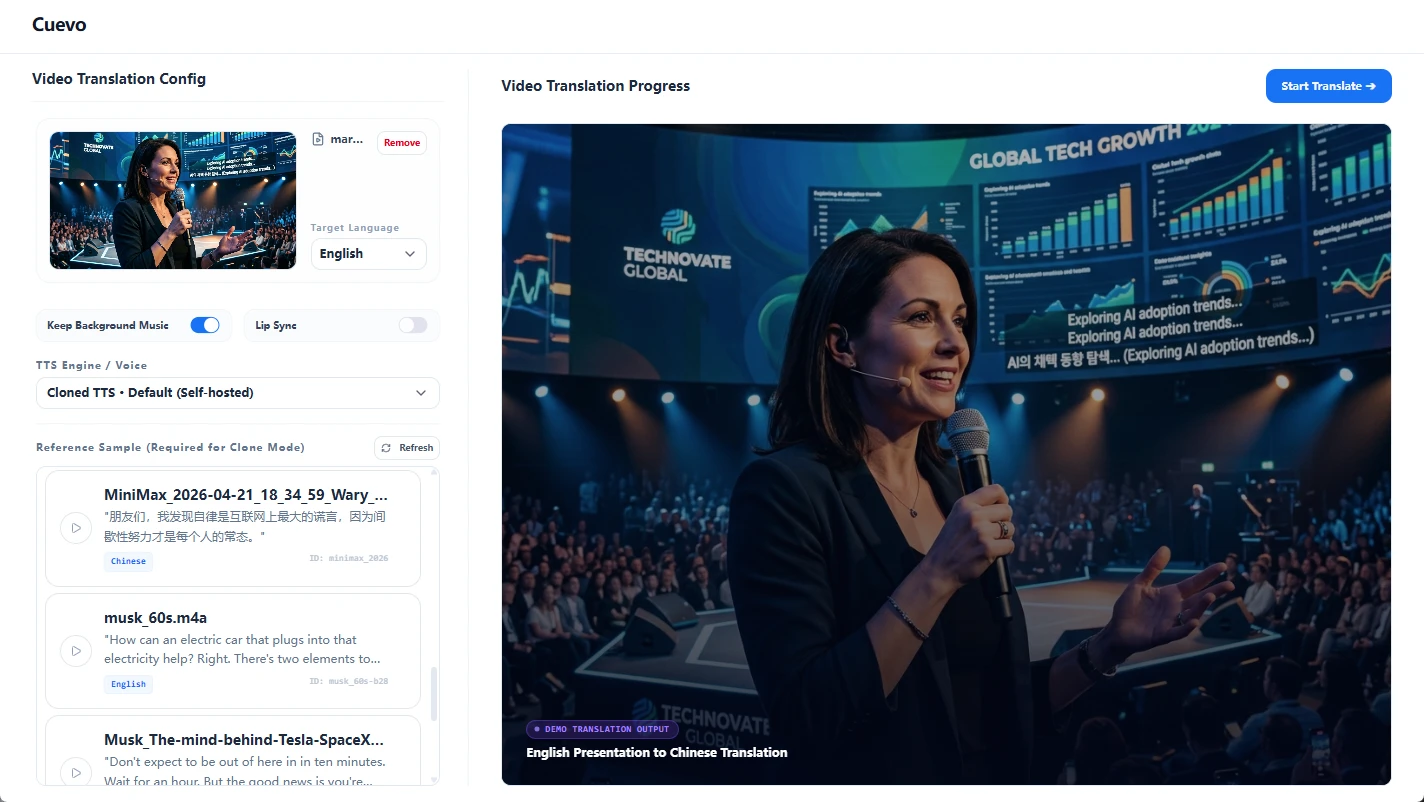
在数分钟内将您的视频资产翻译成 100 多种全球语言。智能翻译引擎不仅能自动转化台词,还会完美保留原说话人的音色韵味,并自动调整主播的嘴型,实现像素级的口型对齐与本地化体验。
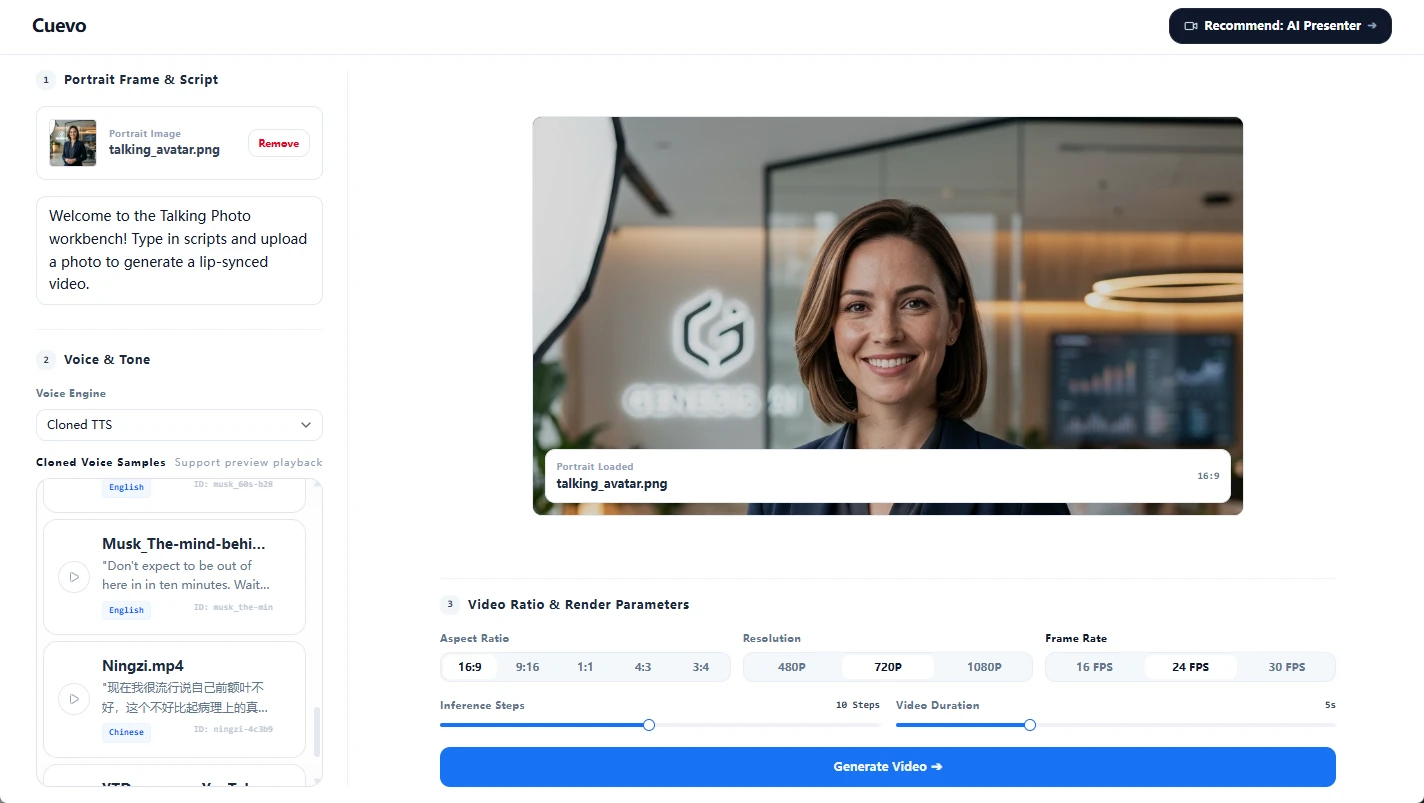
让静态肖像照片、卡通形象或企业吉祥物开口说出任意台词。非常适用于社媒短视频与营销广告,该工具将高分辨率的面部微表情与清晰的配音完美结合,实现即时、生动的视觉讲演。
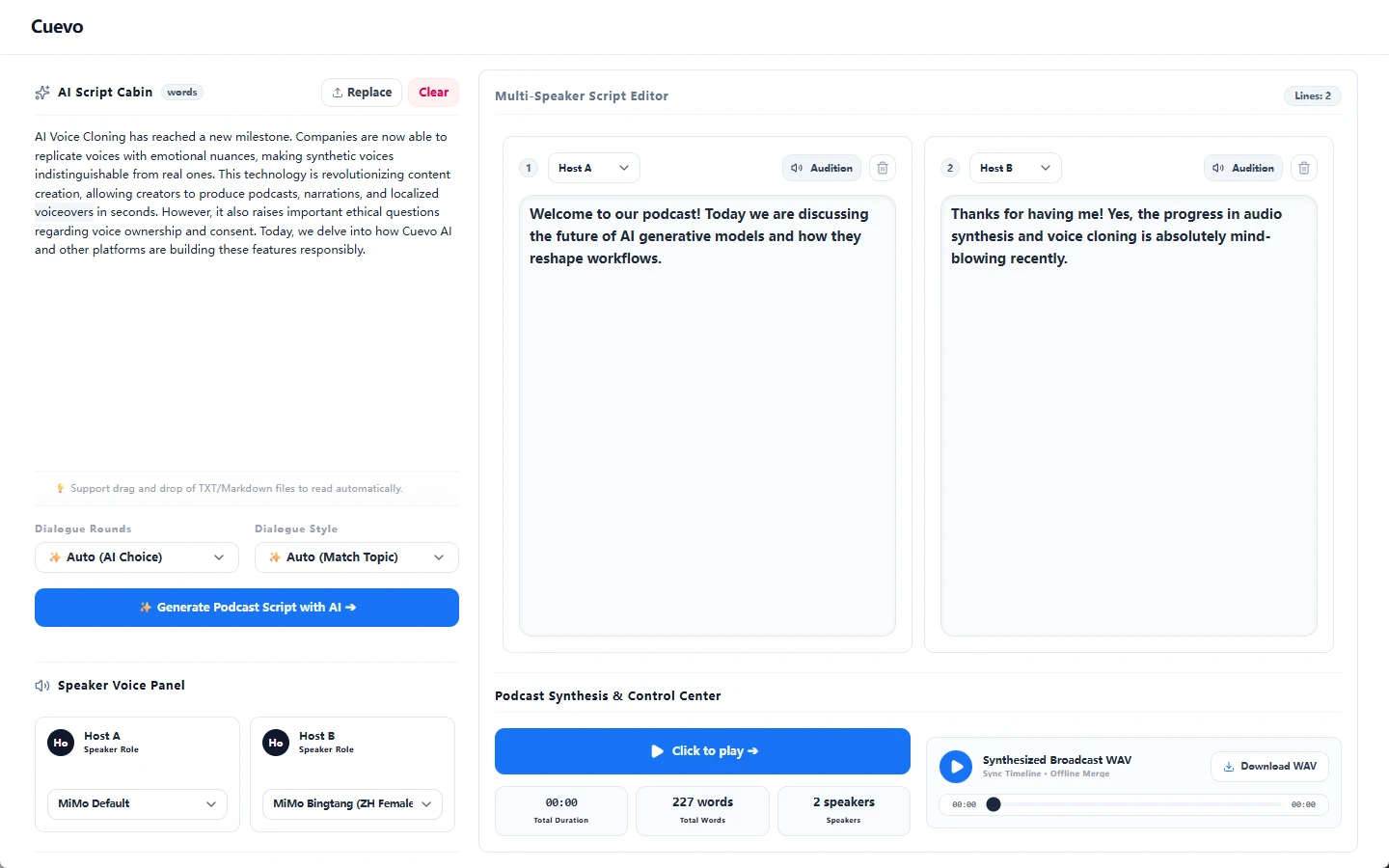
将简单的对话文本或研究文献一键转化为专业级的多数字人对谈播客。在不同风格的虚拟主持人之间建立极其自然、流畅的对话逻辑,并精准还原真实的人声语气起伏和合理的探讨节奏。
为静态图片和视觉插画注入灵动的电影级镜头轨迹。Cuevo 的视觉引擎能够模拟自然的采光变化、逼真的摇移镜头以及三维空间景深,瞬间将静止的图像转化为极具吸引力的视频画面。
实现任意外部导入音轨与数字人画面之间像素级的精准对齐。Cuevo 的神经网络嘴形映射大模型能确保极其流畅、自然的口型同步,让您的定制配音与视频画面高度贴合,消除违和感。
低延迟响应的视频会议与直播交互
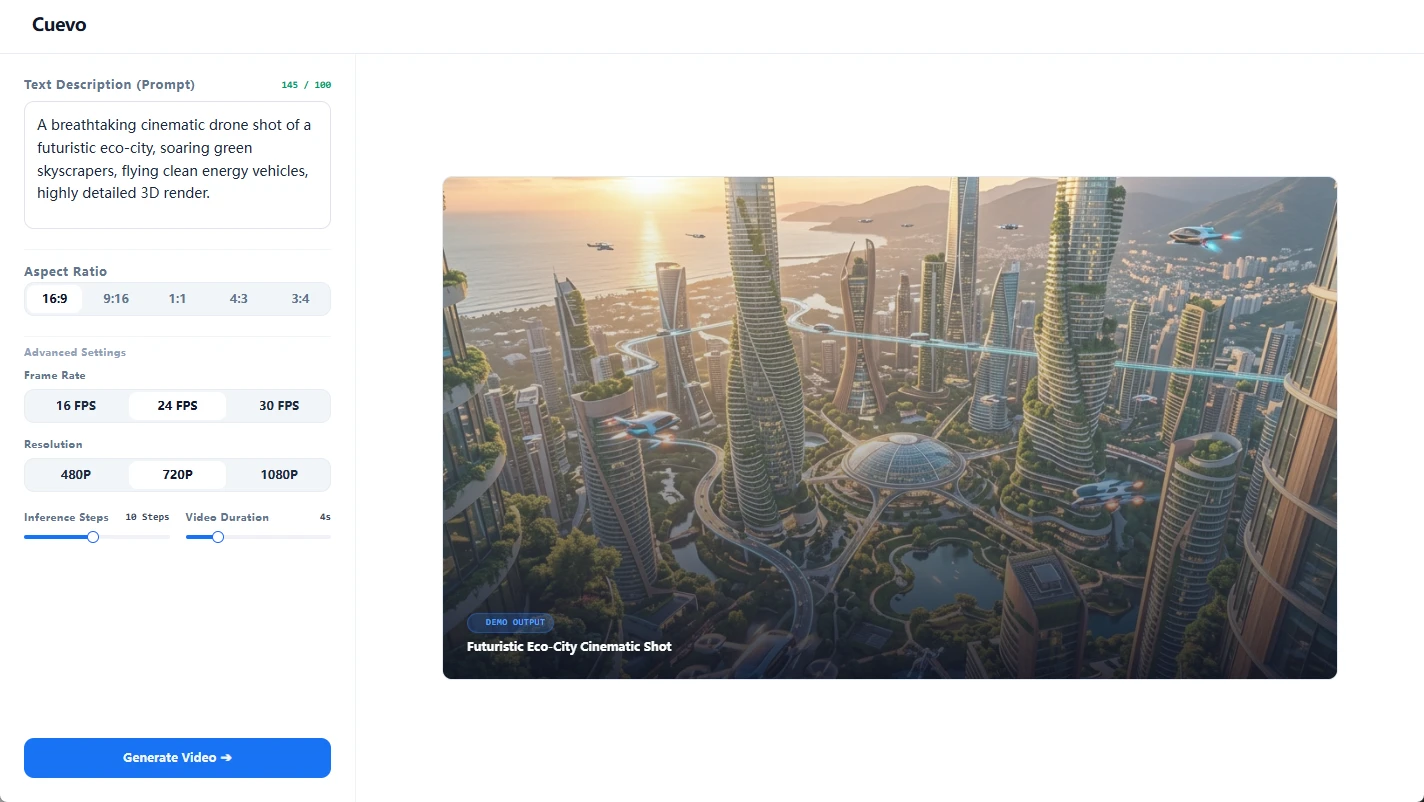
AI 视频生成器
核心视频生成套件,支持各种素材拼接与智能剪辑
声音克隆
以极高的声音拟真度完美复刻任何独特的真人声线。仅需分析简短的音频样本,我们的语音大模型即可支持丰富的情感韵律合成、自然的语调起伏,并实实现在全球 100 多种语言中的无缝配音。
多语言视频翻译
在数分钟内将您的视频资产翻译成 100 多种全球语言。智能翻译引擎不仅能自动转化台词,还会完美保留原说话人的音色韵味,并自动调整主播的嘴型,实现像素级的口型对齐与本地化体验。
静态照片讲解
让静态肖像照片、卡通形象或企业吉祥物开口说出任意台词。非常适用于社媒短视频与营销广告,该工具将高分辨率的面部微表情与清晰的配音完美结合,实现即时、生动的视觉讲演。
对话播客制作
将简单的对话文本或研究文献一键转化为专业级的多数字人对谈播客。在不同风格的虚拟主持人之间建立极其自然、流畅的对话逻辑,并精准还原真实的人声语气起伏和合理的探讨节奏。
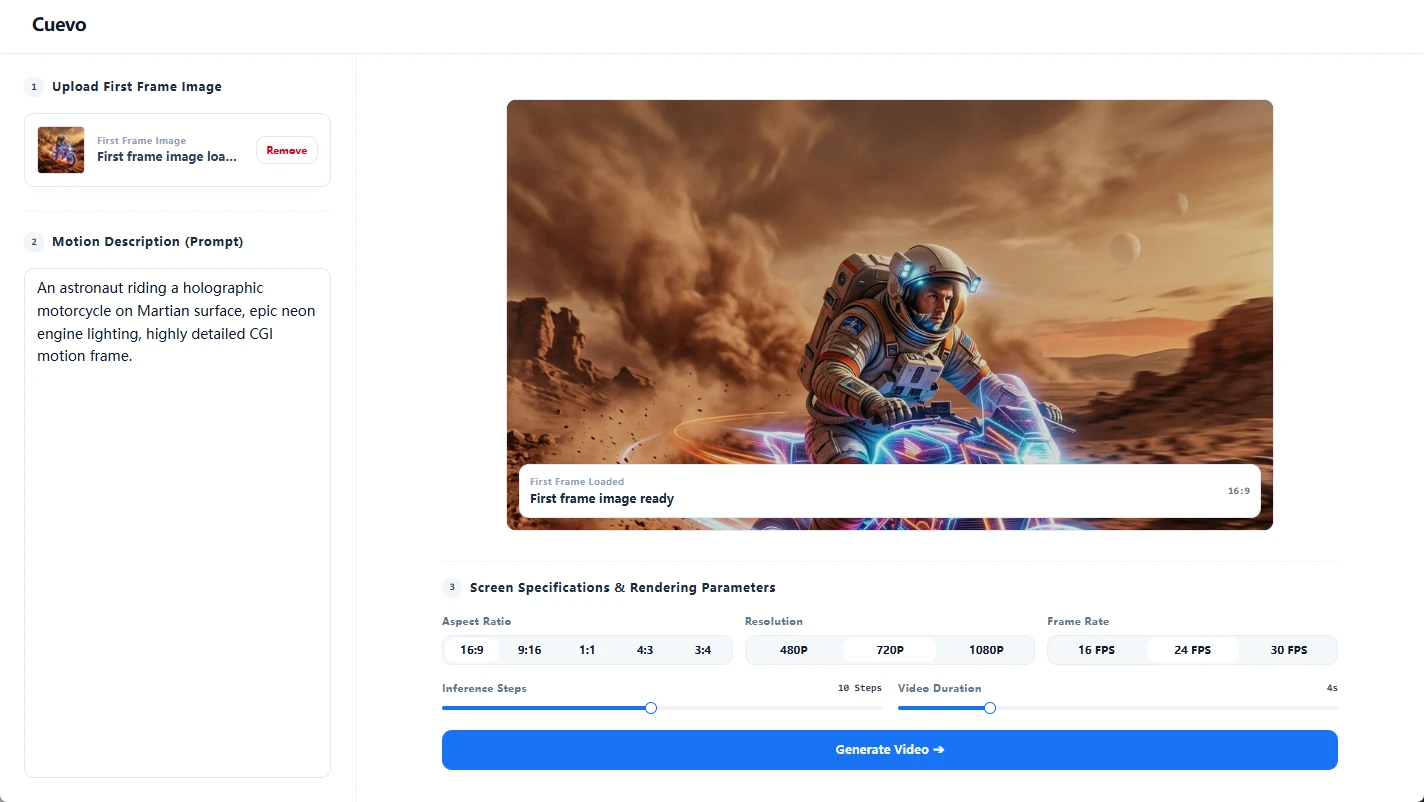
画面转视频
为静态图片和视觉插画注入灵动的电影级镜头轨迹。Cuevo 的视觉引擎能够模拟自然的采光变化、逼真的摇移镜头以及三维空间景深,瞬间将静止的图像转化为极具吸引力的视频画面。
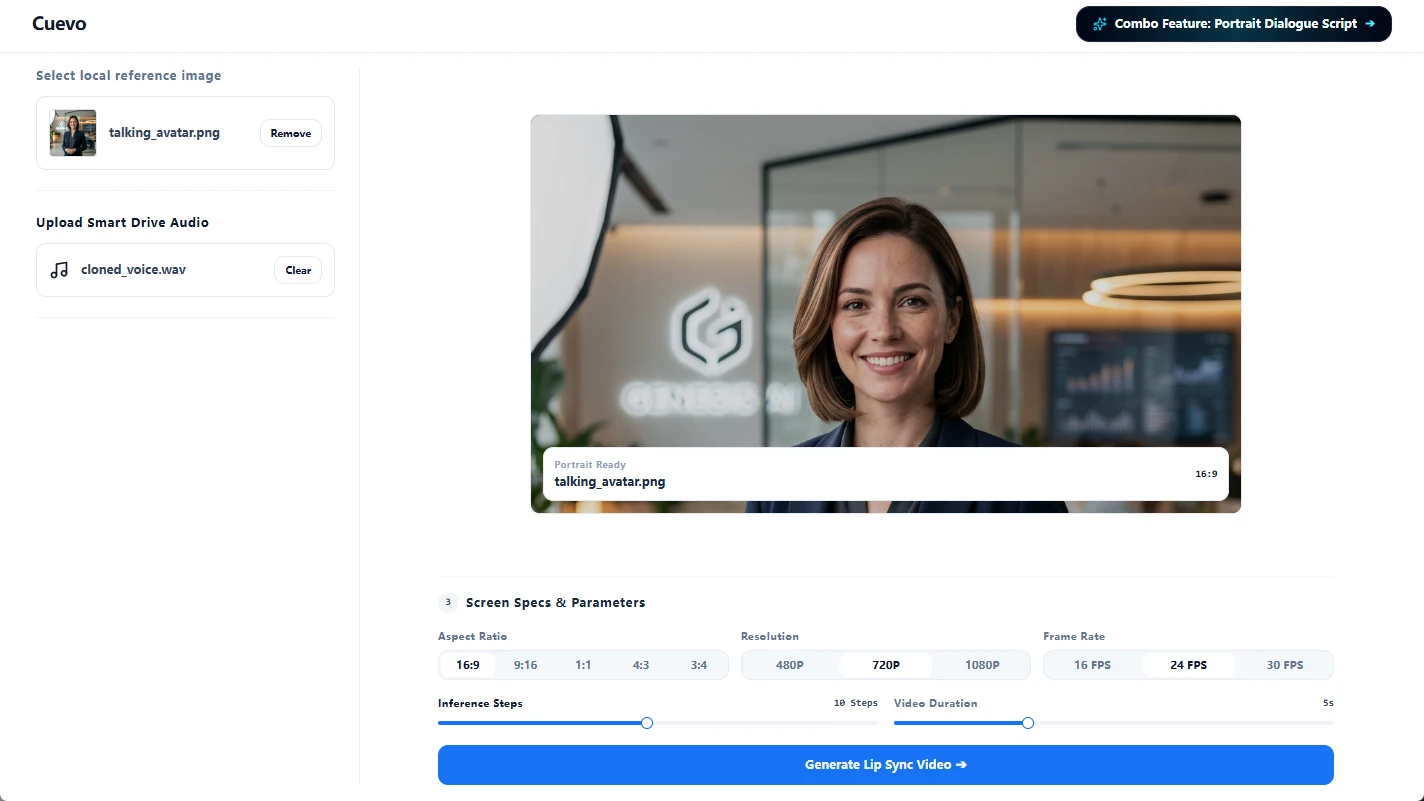
智能口型匹配
实现任意外部导入音轨与数字人画面之间像素级的精准对齐。Cuevo 的神经网络嘴形映射大模型能确保极其流畅、自然的口型同步,让您的定制配音与视频画面高度贴合,消除违和感。
实时数字人
低延迟响应的视频会议与直播交互
为什么选择 Cuevo?
告别低质的传统生成工具,拥抱极致专业的导演工作流。
因对事实的坚持而备受青睐
"The zero-hallucination engine completely revolutionized our financial reporting. It saves our team immense time weekly while delivering broadcast-grade presenter videos."
"预设驱动的 AI 播报员手势控制是真正的创新。丰富的动作预设库能让数字人肢体语言自然顺畅,毫秒级音频口型对齐。"
"Academic PDF smart retrieval and outline generation is astounding. Extracting core logic in seconds dramatically boosted our explainer video workflow."
"The zero-hallucination engine completely revolutionized our financial reporting. It saves our team immense time weekly while delivering broadcast-grade presenter videos."
"预设驱动的 AI 播报员手势控制是真正的创新。丰富的动作预设库能让数字人肢体语言自然顺畅,毫秒级音频口型对齐。"
"Academic PDF smart retrieval and outline generation is astounding. Extracting core logic in seconds dramatically boosted our explainer video workflow."
"Die VFX-Karten und Code-Terminals sind fantastisch! Komplexe Software-Architekturen lassen sich damit extrem anschaulich präsentieren."
"Voice cloning combined with photorealistic avatars is virtually indistinguishable from real life. Cloud parallel rendering is blazingly fast."
"自動B-Rollカットタイミングコンパイラは革新的で、編集時の素材探しにかかる時間を80%以上削減してくれました。"
"Die VFX-Karten und Code-Terminals sind fantastisch! Komplexe Software-Architekturen lassen sich damit extrem anschaulich präsentieren."
"Voice cloning combined with photorealistic avatars is virtually indistinguishable from real life. Cloud parallel rendering is blazingly fast."
"自動B-Rollカットタイミングコンパイラは革新的で、編集時の素材探しにかかる時間を80%以上削減してくれました。"
常见问题解答
您想了解的关于平台的每一件事。
Cuevo 是如何保证数据零幻觉的?
我们的引擎能够智能检索与无损解析相关学术 PDF 文档、Markdown 结构化文档与 TXT 文本,同时自动联网检索交叉验证事实,并以精确的 3D 悬浮图表在视频中还原,杜绝任何 AI 瞎编现象。
我可以完全控制数字人的动作吗?
完全可以!通过工作台内置的姿态预设库 (Action Presets),您可以自由勾选挥手致意、摊手解释、重点强调等 30+ 种动作预设,精准调度数字人的肢体动作与播报仪态。
目前支持导入哪些格式的源文件?
平台原生支持智能检索学术 PDF 文档,并高效支持 Markdown 和 TXT 纯文本文件的极速视频转化。
是否提供面向开发者的 API 接入?
是的,我们的企业定制版(Enterprise)提供完善的高并发 API 接口,支持通过代码级指令实现大规模数字人视频的自动化生产。